
9·
3 days agoSad because the UK’s quite small/unsunny and that means most other countries aren’t doing much?
I thought that the UK was quite strong in wind, so it’d be interesting to see that charted.
New account since lemmyrs.org went down, other @Deebsters are available.
Sad because the UK’s quite small/unsunny and that means most other countries aren’t doing much?
I thought that the UK was quite strong in wind, so it’d be interesting to see that charted.
[MIT] does not allow removing the original license and purport that the code was created by someone else.
Sounds like it wouldn’t matter which licence he used. Shitty behaviour from Microsoft.
I love how short this article is; it’s really respectful of the reader’s time.
Forgejo v11.0 is availablet ?

I’m not sure about the exact setup (default or yours), but is it possible that there’s a prettifier that’s responsible?
Not quite what you were asking for, but there is https://tomgroenwoldt.github.io/helix-shortcut-quiz/
It’s quite good for letting you know about things you didn’t know you could do, but sometimes it tells me I’m wrong because I’d do it a different way - e.g. I’d go to line 13 by :13 but it wants 13G.
Also, from within Helix you can do space ? to get the list of commands and any bindings they’re on.
edit: also, FYI Helix and similar are modal, not modular (although there is a plugin system on the way).
Still interesting, though. I looked for any more up-to-date news and didn’t find any articles, although the ISP’s site says they’re expanding in 2025.

I have Tasker running, and you can set it up to do this too. Between ntfy and Google’s version I think I’m covered already!
Most of the manga I have is amateur translated stuff, so the metadata quality varies with release groups.
The graphic novels are generally retail releases, but sometimes I still want to edit to get rid of marketing words (e.g. the title might mention how it’s now a Netflix series or something).
I guess I’ve just been lucky then! I’ve stripped DRM off everything else, so I expect theirs would come off using the same tools.
The latest Kindle update broke the jailbreak even if it was installed, so you’ll need to stop updates. You could just leave it in airplane mode, but not being able to use the internet to pull down books from your Calibre-web server means you may as well just send books via Calibre.
I’m planning on getting a Kobo Clara BW when my Kindle dies (it’s currently got holes at the corners and a few dodgy-sounding rattles so soon™). Then I can use Koreader+Calibre-web to download books and sync read state like you can do with Amazon.
So your process here is get comics -> comictagger -> upload to server and kavita, correct?
Pretty much, apart from that I often add them and only fix if necessary, e.g. they’re not going into series properly.
None of the books I’ve bought from kobo.com have DRM.
I went with ntfy as well - you can set the different levels to alert in different ways and my max priority is set to always ring even if the phone is on silent. Mostly I use max prio as a find-my-phone tool, but there are real alerts that would use it.
Ebooks: I use Calibre locally and Calibre-web on the server (read-only metadata db, I overwrite with the Calibre version as tagging, etc is far easier on desktop).
You can connect Koreader to Calibre-web and until maybe a fortnight ago you could jailbreak a Kindle and use Koreader instead of the default software. Now you’ll need to manually move files over, or use the email-to-Kindle option (probably a bad idea, but I expect Amazon can tell if you’ve side loaded pirated content anyway). Nowadays I buy from not-Amazon sources, strip any DRM and send it over.
Manga/comics/graphic novels: I use Kavita on the server and I use comictagger on desktop to fix the metadata.
I’m happy to use different set ups for the different types as they’re quite different experiences and specialist tools work better.
I’m using a bunch simultaneously at this point. I need to script keeping them all in sync, or decide which one will be the winner.

Look at bottom centre
Edit: I’m getting upvotes but I’m not technically in the right here…
It uses a neutral net that he designed and trained, so it is AI. The public’s view of “AI” seems mostly the generation stuff like chatbots and image gen, but deep learning is perfect for science and medical fields.
I found his paper: https://iopscience.iop.org/article/10.3847/1538-3881/ad7fe6 (no paywall 😃)
From the intro:
VARnet leverages a one-dimensional wavelet decomposition in order to minimize the impact of spurious data on the analysis, and a novel modification to the discrete Fourier transform (DFT) to quickly detect periodicity and extract features of the time series. VARnet integrates these analyses into a type prediction for the source by leveraging machine learning, primarily CNN.
They start with some good old fashioned signal processing, before feeding the result into a neutral net. The NN was trained on synthetic data.

FC = Fully Connected layer, so they’re mixing FC with mostly convolutional layers in their NN. I haven’t read the whole paper, I’m happy to be corrected.

I think I’ll wait for a better source than the Daily Mail before I consider it dead.





















{kind=link}
{kind=link}
{kind=link}
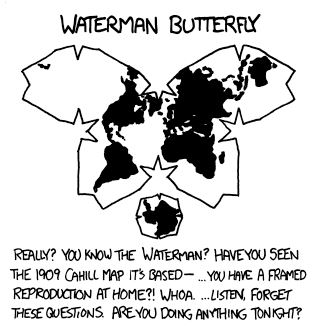
It is a map, though, unlike OP’s image!